Transformez vos documents privés en chatbot IA : la méthode simple avec Streamlit, Ollama et ChromaDB
Vous avez des dossiers remplis de PDF et vous rêvez de les interroger comme si vous parliez à un collègue ? Plus besoin de monter une infrastructure complexe avec des API multiples. Aujourd’hui, il est possible de tout centraliser dans une seule application.
Voici comment bâtir un outil de chat documentaire souverain, performant et 100 % local.
1. L’Architecture : le circuit court de l’information
Le processus suit une logique rigoureuse de traitement de la donnée, appelée RAG (Retrieval-Augmented Generation).
Comment l’information circule-t-elle ?
- L’Ingestion : vous déposez vos PDF dans l’interface.
- Le Découpage (Chunking) : le texte est segmenté en petits morceaux afin que l’IA puisse traiter l’information de manière ciblée sans être saturée.
- Le Stockage (ChromaDB) : ces segments sont transformés en vecteurs (représentations mathématiques) et stockés localement dans ChromaDB. C’est votre « bibliothèque de recherche » qui permet de retrouver instantanément un paragraphe à partir de son sens.
- La Discussion (Ollama) : quand vous posez une question, l’application recherche les segments les plus pertinents dans ChromaDB. Elle les transmet ensuite à Ollama, qui utilise un modèle de langage pour rédiger une réponse précise basée sur ces extraits.
2. Implémentation de la stack technique
Pour réaliser ce projet, nous n’avons besoin que de trois briques, toutes intégrées en Python :
🧠 Le Cerveau : Ollama
Pour garantir la confidentialité des données, nous privilégions une solution locale plutôt que des services tiers. Cela permet d’utiliser des modèles puissants (comme le modèle IBM Granite4) sans qu’aucune information ne quitte votre ordinateur.
Vous pouvez installer Ollama et le modèle d’IBM en suivant les commandes suivantes :
curl -fsSL https://ollama.com/install.sh | sh
Puis :
ollama pull granite4:latest # ou un autre modèle de votre choix
Une fois l’installation terminée, nous pouvons configurer le projet Python. Nous utiliserons ici uv pour la gestion des dépendances :
# Installer UV curl -LsSf https://astral.sh/uv/install.sh | sh # Créer le projet uv init mon-projet cd mon-projet
Créez un dossier services, puis les deux fichiers suivants :
limiter.py: il servira de limitateur de débit (Rate Limiter) pour stabiliser l’application.
import time
import threading
class RateLimiter:
"""
Implémente un algorithme de Token Bucket pour limiter le débit.
Thread-safe pour une utilisation fluide.
"""
def __init__(self, max_calls_per_second=10):
self.rate = max_calls_per_second
self.tokens = max_calls_per_second
self.last_update = time.time()
self.lock = threading.Lock()
def wait_for_slot(self):
with self.lock:
current_time = time.time()
time_passed = current_time - self.last_update
self.tokens += time_passed * self.rate
if self.tokens > self.rate:
self.tokens = self.rate
self.last_update = current_time
if self.tokens >= 1:
self.tokens -= 1
return
else:
needed = 1 - self.tokens
wait_time = needed / self.rate
self.tokens -= 1
if wait_time > 0:
print(f"⏳ Limite atteinte. Attente de {wait_time:.4f}s...")
time.sleep(wait_time)
llm.py: l’outil qui appellera l’IA. Installez d’abord les librairies nécessaires :
uv add langchain_ollama langchain
Voici le code de l’agent :
from langchain_ollama import ChatOllama
from langchain.agents import create_agent
from services.limiter import RateLimiter
# 1. SETUP DE L'AGENT PRINCIPAL (OLLAMA)
llm_ollama = ChatOllama(
model="granite4:7b-a1b-h",
temperature=0,
timeout=10
)
TOOLS = []
agent_executor = create_agent(
model=llm_ollama,
tools=TOOLS,
system_prompt="Vous êtes un assistant professionnel. Utilisez les outils si nécessaire."
)
# 2. MANAGER DE L'IA
class AIProviderManager:
"""Gère la logique : Rate Limit -> Agent Local."""
def __init__(self):
self.limiter = RateLimiter(max_calls_per_second=10)
def call(self, messages):
self.limiter.wait_for_slot()
try:
print("🤖 Tentative avec l'agent Ollama...")
response = agent_executor.invoke({"messages": messages})
return response['messages'][-1].content
except Exception as e:
raise e
🗄 La Mémoire : ChromaDB
Il faut maintenant donner au chatbot l’accès à une base de connaissances alimentée par vos PDF. Pour éviter de surcharger le LLM, nous allons segmenter (« chunker ») les documents via un fichier parser.py dans services/.
Installez la dépendance suivante :
uv add pymupdf4llm
parser.py: contient les méthodes pour convertir et découper le texte.
import pymupdf4llm
from typing import List, TypedDict
class Chunk(TypedDict):
fileName: str
title: str
content: List[str]
class Parser:
def __init__(self):
return
def pdf_to_markdown(self, path: str):
md_text = pymupdf4llm.to_markdown(path)
return md_text
def markdown_to_chunks(self, file_name: str, markdown: str) -> List[Chunk]:
# Séparer par ligne et filtrer les lignes vides
lines = [line for line in markdown.split("\n") if line.strip() != ""]
chunks: List[Chunk] = []
current_chunk: Chunk | None = None
for line in lines:
is_title = line.startswith("#")
current_title_level = len(line.split(" ")[0]) if is_title else 0
last_title_level = 0
if current_chunk and current_chunk["title"].startswith("#"):
last_title_level = len(current_chunk["title"].split(" ")[0])
if is_title and current_chunk and current_title_level == last_title_level:
current_chunk["title"] += line
elif is_title:
if current_chunk:
chunks.append(current_chunk)
current_chunk = {
"fileName": file_name,
"title": line,
"content": []
}
else:
if current_chunk:
current_chunk["content"].append(line)
else:
# Si pas de titre encore, commence un chunk avec un titre par défaut
current_chunk = {
"fileName": file_name,
"title": file_name,
"content": [line]
}
if current_chunk:
chunks.append(current_chunk)
reduced_chunks: List[Chunk] = []
for chunk in chunks:
if len(chunk["content"]) == 1 and len(reduced_chunks) > 0:
reduced_chunks[-1]["content"].append(chunk["content"][0])
reduced_chunks[-1]["content"] = list(
dict.fromkeys(reduced_chunks[-1]["content"]))
elif len(chunk["content"]) > 1:
reduced_chunks.append(chunk)
chunks = reduced_chunks
# Si pas de titre dans le fichier entier, fusionne en un seul chunk
has_real_title = any(chunk["title"] != file_name for chunk in chunks)
if not has_real_title and len(chunks) > 1:
# Équivalent de chunks.flatMap((c) => c.content)
flat_content = [item for c in chunks for item in c["content"]]
return [
{
"fileName": file_name,
"title": file_name,
"content": flat_content,
}
]
return chunks
Créez ensuite un dossier entities/ avec un fichier document.py pour définir le schéma de stockage :
import uuid
class Document:
def __init__(self, text: str, id: str | None = None, metadata: dict | None = None):
self.id = id if id is not None else str(uuid.uuid4())
self.text = text
self.metadata = metadata
@staticmethod
def generateFilter(data: dict):
return Document("", None, data)
Enfin, créez vectorestore.py pour gérer ChromaDB :
from chromadb import PersistentClient, Collection
from chromadb.utils import embedding_functions
from typing import Optional, List
from entities.document import Document
embed_fn = embedding_functions.DefaultEmbeddingFunction()
class VectoreStore:
def __init__(self, collection_name: str = "test"):
client = PersistentClient(path="./chroma_store")
self.collection: Optional[Collection] = client.get_or_create_collection(
name=collection_name)
def add(self, document: Document):
self.collection.add(
ids=[document.id],
documents=[
document.text,
],
metadatas=[document.metadata]
)
return
def delete(self, filterData: Document):
if not filterData.metadata:
all_ids = self.collection.get(include=[])["ids"]
self.collection.delete(
ids=all_ids
)
return
self.collection.delete(
where=filterData.metadata
)
def get(self, text: str, n_results: int = 4):
results = self.collection.query(
query_texts=[text],
n_results=n_results
)
documents_results: List[Document] = []
ids = results['ids'][0]
documents = results['documents'][0]
metadata = results['metadatas'][0]
for i, id in enumerate(ids):
doc = documents[i]
document = Document(text=doc, id=id, metadata=metadata)
documents_results.append(document)
return documents_results
🎨 L’Interface : Streamlit
C’est le chef d’orchestre qui gère l’interface et la synchronisation.
uv add streamlit
Code de main.py :
import streamlit as st
import os
from services.parser import Parser
from entities.document import Document
from services.vectoreStore import VectoreStore
from services.llm import AIProviderManager
# --- Page Config ---
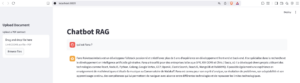
st.set_page_config(page_title="Contract AI Assistant", layout="wide")
st.title("Chatbot RAG")
# --- Initialization ---
if "store" not in st.session_state:
st.session_state.store = VectoreStore()
st.session_state.parser = Parser()
st.session_state.client = AIProviderManager()
st.session_state.messages = []
st.session_state.indexed_file = None
# --- Sidebar: File Upload ---
with st.sidebar:
st.header("Upload Document")
uploaded_file = st.file_uploader("Upload a PDF contract", type="pdf")
if uploaded_file and st.session_state.indexed_file != uploaded_file.name:
with st.spinner("Parsing and indexing document..."):
temp_path = os.path.join("./temp_", uploaded_file.name)
os.makedirs("./temp_", exist_ok=True)
with open(temp_path, "wb") as f:
f.write(uploaded_file.getbuffer())
print(f"reading : {temp_path} ...")
markdown = st.session_state.parser.pdf_to_markdown(temp_path)
print("chunking ...")
chunks = st.session_state.parser.markdown_to_chunks(
uploaded_file.name, markdown)
for chunk in chunks:
doc = Document(
"\n".join(chunk['content']),
None,
metadata={"title": chunk['title']}
)
st.session_state.store.add(doc)
print(f"{doc.metadata}")
st.session_state.indexed_file = uploaded_file.name
st.success("Document indexed!")
# --- Chat Interface ---
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# User Input
if prompt := st.chat_input("Ask something about the document..."):
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
# RAG Logic
with st.chat_message("assistant"):
with st.spinner("Thinking..."):
# 1. Retrieval
documents = st.session_state.store.get(prompt)
context = [doc.__dict__ for doc in documents]
# 2. Augmentation
full_prompt = f"Context: {context}\n\nQuestion: {prompt}"
# 3. Generation
response = st.session_state.client.call(
{"role": "user", "content": full_prompt})
st.markdown(response)
st.session_state.messages.append(
{"role": "assistant", "content": response})
Lancement de l’application :
Bash
uv run streamlit run main.py
Rendez-vous sur : http://localhost:8501/
3. Pourquoi c’est une solution d’avenir ?
Passer par une solution locale et intégrée lève le principal frein à l’adoption de l’IA : la sécurité des données. – Confidentialité absolue : vos informations restent sur votre machine ou serveur privé.
- Maîtrise des coûts : aucun frais par jeton (token). Seule l’énergie consommée compte.
- Indépendance technologique : vous ne dépendez d’aucun fournisseur externe ou changement de conditions tarifaires.
Conclusion
Le « Chat documentaire » n’est plus un luxe réservé aux géants de la tech. En combinant la souplesse de Streamlit avec la puissance locale d’Ollama, tout professionnel peut désormais transformer sa base de connaissances en un actif interactif et sécurisé.