
La date est fixée, dans moins de 3 semaines, le 12 Novembre prochain la première version stable de PHP 7 sera publiée. L’occasion de faire le point sur les nouveautés de ce langage utilisé par plus de 80% des sites et applications web selon les dernières estimations.
Un petit retour en arrière pour commencer
Avant de se pencher sur cette nouvelle version, il peut être intéressant de voir comment ce langage a évolué depuis sa création en 1994 par Rasmus Lerdorf.
A cette époque, Rasmus maintient son site personnel et cherche à garder une trace des consultations sur son CV. Il développe ainsi une bibliothèque en C qu’il enrichit en fonctionnalités au fur et à mesure jusqu’à décider de la publier en 1995 sous le nom de PHP/FI (Personal Home Page Forms Interpreter) puis PHP Tools. Alors qu’il n’a jamais souhaité en faire un langage de programmation en tant que tel, l’engouement nait autour du projet et une équipe de développement se forme faisant évoluer la bibliothèque en un langage jusqu’à la publication d’une version 2 en 1997. A cette époque, le nouveau langage essuie de nombreuses critiques car il manque cruellement de consistance tant au niveau du nommage de ses fonctions que sur l’ordonnancement de leurs paramètres.
C’est à ce moment que deux développeurs (Zeev Suraski et Andi Gutmans) se lancent dans le projet en commençant par réécrire le parseur en collaboration avec Rasmus. PHP 3 qui devient un acronyme « PHP Hypertext Preprocessor », commence à ressembler à notre PHP moderne avec un début de support de la programmation orientée objet, un support de nombreuses bases de données mais également des possibilités d’extension qui continuent de rassembler une communauté autour du projet. PHP 3 est installé sur plus de 10% des serveurs web à l’époque.
Fort de ce succès, Zeev et Andi se concentrent sur le cœur de PHP qui deviendra le Zend Engine (formé de leur 2 prénoms ZEev et aNDi) et donnera naissance à la société du même nom. Le Zend Engine est intégré à la nouvelle version de PHP 4 publiée en 2000 tout en conservant une bonne compatibilité avec la version antérieure. Les grandes nouveautés de PHP 4 sont l’output buffering, l’intégration de l’opérateur « === », l’intégration des composants COM Windows et un changement de licence (PHP Licence très proche de la licence BSD).
Il faudra attendre 4 années supplémentaires pour voir arriver la version moderne de PHP que nous connaissons, la version 5, qui apporte son lot de nouveautés. Le modèle objet est ainsi complètement remanié avec, entre autres, l’apparition des constructeurs/destructeurs modernes, la portée des variables jusque lors uniquement publique, les interfaces et classes abstraites, la gestion des exceptions, etc. C’est également l’arrivée de PDO, SQLite ou encore SimpleXML.
PHP se professionnalise donc et l’engouement autour de lui ne se dément pas. Au contraire, il continue à croître, encouragé par son adoption par les grands noms du web comme Yahoo ou encore Facebook.
En 2005, Andrei Zmievski entreprend d’offrir à PHP un support natif d’Unicode en embarquant la librairie ICU (International Components for Unicode) afin de répondre aux critiques de certains développeurs sur l’absence de celui-ci. L’implémentation choisie requiert une représentation interne des chaînes de caractères en UTF-16 mais l’équipe se heurte à des problèmes de performances et manque d’experts en Unicode. Après avoir été maintes fois reporté, le projet est finalement abandonné. Toutes les évolutions du langage prévues autres que l’Unicode, sont reportées sur les versions 5.3 (namespaces, fonctions anonymes) et 5.4 (traits) respectivement en 2009 puis 2012.
En parallèle, un cycle programmé de publication des nouvelles versions est voté et adopté en 2010.
Celui-ci prévoit une nouvelle version du langage tous les ans ainsi qu’une durée de support de 3 ans pour chacune d’elles (2 ans de correctifs puis 1 an de patchs de sécurité uniquement) et une rétrocompatibilité entre toutes les versions mineures (5.x par exemple).
Voté ?
Oui, les plus attentifs auront remarqué que cette décision a été votée.
En effet, depuis 2011, chaque évolution du langage fait l’objet d’une proposition de RFC disponible sur le wiki de PHP (https://wiki.php.net/rfc) qui est votée à l’issue d’une période de discussion.
L’ensemble des contributeurs de PHP (c’est-à-dire les détenteurs d’un compte SVN) ainsi que des personnes représentatives de la communauté PHP (Lead developers de frameworks, CMS ou autres composants répandus) peuvent prendre part au vote. Chaque proposition doit recueillir au moins la majorité absolue pour être acceptée, voire 2/3 des votes pour les propositions ayant un impact fort sur le langage (nouvelle syntaxe par exemple).
C’est ainsi que l’ensemble des nouveautés du langage dans sa version 7 a été soumis au vote jusqu’à sa dénomination en PHP 7.
PHP 6 vs PHP 7
La version actuelle de PHP étant la 5.6, il aurait été assez logique que la nouvelle version majeure de PHP prenne le numéro 6.
Cette question a été au centre du débat il y a un an, amené par la RFC « Name of Next Release of PHP » en Juillet 2014 de 2 contributeurs (dont Zeev Suraski, un des auteurs du Zend Engine pour ceux qui suivent ;-)).
Les arguments majeurs en faveur de PHP 7 furent :
- PHP 6 est le nom d’un projet qui a déjà existé, qui est documenté (il existe de nombreux articles sur PHP 6) et qui est connu de la plupart des membres de la communauté PHP. Cela pourrait être donc source de confusion.
- De nombreux projets ont déjà sauté des pas dans la numérotation des versions de leurs projets (MariaDB par exemple est passé de la version 5.5 à la version 10.0). Il y a donc des précédents.
- La version 6 est généralement associée à l’échec dans le monde des langages (Le précédent projet PHP 6 ne fait pas exception mais on peut également citer Perl 6 ou encore MySQL 6 qui n’a jamais été publié).
- Le chiffre 7 est un porte bonheur dans de nombreuses cultures (non celle-ci n’était pas sérieuse ;-))
Ces arguments l’emportent lors du vote à 58 voix contre 24, la nouvelle version majeure de PHP sera donc la 7.
Il est temps désormais de rentrer dans le vif du sujet et d’aborder les principales nouveautés du langage.
HHVM vs PHPNG : PHP Next Generation
Vous avez certainement déjà entendu parler de HHVM ou HipHop for PHP.
HipHop est un compilateur créé par Facebook en 2008 qui permet de transformer puis compiler du code PHP 5.2 en C++ afin d’améliorer les performances à l’exécution et de gagner en ressources serveur. Ce produit a évolué ensuite en HHVM (pour HipHop Virtual Machine) à partir de 2010 reposant cette fois-ci sur une compilation Just In Time (ou à la volée). Cette technologie a eu le vent en poupe ces dernières années permettant d’atteindre des performances plus que doublées dans certains usages par rapport à un couple Apache/PHP 5.x ou Nginx/PHP 5.x-FPM par exemple.
PHPNG peut être vu comme la riposte de Zend à HHVM.
En Mai 2014, une branche fait son apparition sur le SVN de PHP afin d’étudier l’implémentation native de la compilation JIT à PHP. Finalement, le projet tourne au nettoyage de printemps, les APIs core sont épurées et les structures internes de données sont modifiées permettant une amélioration conséquente des performances et de l’utilisation mémoire. Une RFC propose son intégration à la version 7 de PHP et est adoptée à la quasi-unanimité.
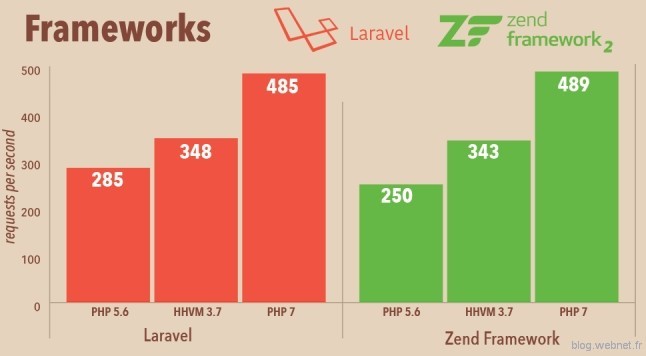
Beaucoup de benchmarks sont sortis ces derniers temps tendant à démontrer le gain en performance de PHPNG (et donc PHP 7) par rapport à PHP 5.6 et HHVM. Si on prend l’un de ceux réalisés par Zend sur des frameworks répandus (Fig. A), on remarque que l’on approche d’un gain de 100% par rapport à PHP 5.6 et que PHPNG surpasse HHVM. Il faut cependant prendre ces chiffres avec prudence. Les benchmarks sont souvent réalisés sur des calculs ou des portions de code qui ne reflètent en rien une application typique et un cas concret. De plus, et c’est le cas de Zend, l’auteur du benchmark est souvent parti pris dans la comparaison et on peut gager qu’il met principalement en avant les cas qui sont à son avantage.
Si on regarde l’ensemble des benchmarks réalisés par différentes personnes ou organismes, PHPNG et HHVM sont au coude à coude en moyenne. Pour ce qui nous intéresse le plus, le gain de performance est évident entre PHP 5.6 et PHP 7 mais dans une proportion plus raisonnable. N’espérez donc pas diviser par deux le temps de génération des pages de votre application même si le gain se révélera très certainement appréciable.
Un typage plus évolué
C’est certainement l’une des évolutions proposées qui aura le plus déchaîné les passions lors de la phase de discussion de la RFC liée : Le typage scalaire, le typage des valeurs de retour d’une méthode et le typage strict.
Jusque lors, il était possible de typer les paramètres d’entrée d’une fonction mais uniquement pour les objets et tableaux et non pour les types dit « scalaires » (c’est-à-dire int, float, string et bool).
C’est désormais possible mais cela va encore plus loin car il est désormais possible de spécifier également le type de retour d’une fonction. Tout cela n’est bien entendu pas obligatoire mais cela vous permettra d’écrire un code plus propre et vous évitera certainement bien des bugs via la détection d’appels incorrects qu’offrent déjà aujourd’hui de nombreux IDE.
L’autre nouveauté est la possibilité de configurer, à un niveau très strict, le contrôle du type des arguments passés à une fonction. Ainsi, si on active ce comportement en ajoutant la ligne
en première ligne de notre fichier PHP, le code suivant devient incorrect et générera une erreur fatale :
La chaine de caractères ’12’ qui est habituellement castée en un (int) 12 et le (float) 1.5 en un (int) 1 ne seront plus acceptés dans ce cas.
Bien entendu ce comportement est, encore une fois, optionnel et il appartient au développeur de l’activer s’il le souhaite.
De nouveaux opérateurs
La version 7.0 est également l’occasion de voir 2 nouveaux opérateurs faire leur entrée.
Le premier est un opérateur de comparaison combiné (<=>) appelé également « Spaceship operator » en raison de sa forme de vaisseau spacial. Il vient rejoindre la liste des opérateurs de comparaison que nous connaissons bien (==, <=, <, >, >=) mais contrairement à eux il ne renvoie pas une valeur booléenne mais 3 valeurs distinctes.
| Si Droite < Gauche | 5 <=> 6 | -1 |
| Si Droite = Gauche | 6 <=> 6 | 0 |
| Si Droite > Gauche | 6 <=> 5 | 1 |
Cela fonctionne à la fois sur des valeurs numériques (int et float) mais également sur des chaines de caractères, des tableaux et même des objets !
Cela a surtout de l’intérêt dans les algorithmes de tri en réduisant considérablement le code écrit :
Le second opérateur vient compléter avantageusement l’opérateur ternaire existant.
Il se nomme « Null Coalesce Operator » et prend la forme de deux points d’interrogation (??).
Il permet de s’assurer en une seule opération que la variable existe et qu’elle n’est pas nulle.
Si la valeur gauche est définie et n’est pas nulle, elle est retournée. Dans le cas contraire c’est la valeur droite qui est retournée.
Imbrication des « use »
Il est désormais possible de regrouper les déclarations uses en groupe afin de gagner en lisibilité et d’éviter de répéter le même chemin n fois comme ceci :
Interception des erreurs fatales
Si, jusque lors, intercepter une erreur fatale était chose très difficile et même déconseillée, cela est désormais possible en PHP 7.
En effet, une erreur fatale va pouvoir être catchée tout comme une exception l’est aujourd’hui.
Pour cela une nouvelle organisation de l’arborescence a été mise en place :
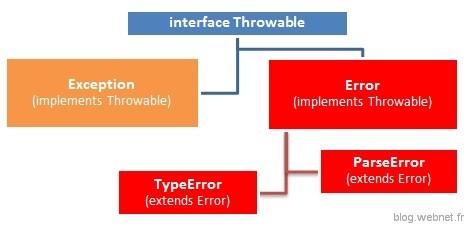
Ainsi, la classe de base des exceptions « Exception » que l’on connaît aujourd’hui implémente désormais une interface « Throwable ». Cette interface regroupe l’ensemble des méthodes actuelles d’une Exception (getMessage(), getTrace(), etc.)
Une nouvelle classe « Error » apparaît qui implémente également cette interface et représente la base d’une erreur remontée par PHP lors de l’exécution. Il est possible ensuite de faire la distinction entre 2 types d’erreurs :
- ParseError : Erreur du parseur PHP lorsque du code est évalué via eval()
- TypeError : Ensemble des autres erreurs rencontrées à l’exécution
Cette nouvelle implémentation a l’avantage d’être compatible avec le code existant aujourd’hui.
En effet, les « catch » de votre code ne risqueront pas d’attraper une erreur fatale et, sans modifications de votre part, les erreurs fatales se comporteront toujours comme elles le font aujourd’hui, c’est-à-dire par une belle page blanche avec quelques lignes noires.
En revanche, il va vous être possible de traiter des erreurs comme ceci par la suite :
Mots réservés et scopes
Suite au typage des valeurs scalaires, les termes « int », « float », « string », « bool », « null », « true », « false », « resource », « objec t », « mixed » et « numeric » deviennent protégés et ne peuvent plus être utilisés en tant que nom de classe, interface ou trait.
En revanche, la liste des mots réservés ayant tendance à s’allonger (plus d’une soixantaine aujourd’hui), il sera désormais possible d’utiliser ces mots pour nommer des membres d’une classe, d’une interface ou d’un trait.
Si, à l’heure actuelle, ce code ne fonctionne pas car les mots « foreach », « list » et « new » sont protégés, dès PHP 7.0, ce code devient valide, PHP prenant en compte le contexte. La seule exception est le mot « class » qui reste interdit dans l’ensemble des contextes.
Abstract Syntax Tree / Uniform Variable Syntax
Jusqu’à la version 5, l’opcode est généré en une passe unique : le parser analyse le code et génère l’opcode qui en résulte. Au-delà du fait que cette approche est peu standard, ce processus en une phase rend difficile ou impossible l’implémentation de certaines syntaxes et nuit à la maintenance et l’évolutivité de l’ensemble.
Une RFC votée à l’unanimité change la donne en implémentant un processus en 3 phases :
- Génération d’un flux de tokens
- Génération d’un AST (Abstract Syntax Tree) à partir de ce flux de tokens
- Génération de l’opcode à partir de la lecture de l’AST
L’AST ou arbre syntaxique abstrait est un arbre dont les nœuds internes représentent les opérateurs et dont les feuilles représentent les variables manipulées. Il permet ainsi de découpler le travail d’analyse du code et de compilation.
Il a également été décidé que l’arbre produit serait exposé via une extension et deviendrait ainsi « hookable ». Cela pourra permettre par exemple de voir apparaître des extensions proposant de nouvelles syntaxes.
Bien que complètement transparente pour le développeur final, cette évolution pourrait avoir des impacts très positifs sur l’évolution du langage, tant en terme de nouvelles fonctionnalités qu’en terme de performances.
La deuxième évolution interne est la remise à plat de la manière dont les expressions sont évaluées via l’implémentation d’une « Uniform Variable Syntax » (syntaxe de variable uniforme). Cette nouveauté cherche à résoudre certaines incohérences dans l’interprétation actuelle des expressions par le moteur PHP.
Si cette évolution a toutes les chances d’être transparente pour vous, elle peut toutefois vous réserver quelques surprises si vous utilisez ce type de syntaxe :
qui signifiait :
et qui signifiera désormais :
Sauf indication contraire, la lecture se fait désormais toujours de gauche à droite.
Il reste toutefois très facile de contourner le problème en ajoutant des accolades sur la partie devant être interprétée prioritairement.
Et après ?
Voici donc les principales nouveautés que la sortie de PHP 7 à la rentrée prochaine nous réserve.
Cette nouvelle version montre que le langage continue de s’améliorer et de se réinventer en permanence tant en performance qu’en structure tout en continuant à répondre aux besoins des développeurs et en n’abandonnant pas ce qui fait de lui un des langages les plus utilisés : sa simplicité.
La migration des applications PHP5 vers PHP7 ne devrait pas poser beaucoup de problèmes, une attention toute particulière ayant été apportée à la rétrocompatibilité.
Rasmus Lerdorf a résumé le problème de la migration comme ceci : « Si votre code a plus de 12 ans il plantera avec PHP 7. S’il fonctionne sous PHP 5, cela devrait bien se passer »
Il est d’ailleurs déjà possible de tester cette version pour les plus pressés d’entre vous.
A l’heure de la publication de cet article, la RC5 a été publiée et une nouvelle RC est prévue tous les 15 jours jusqu’au 14 Novembre. N’hésitez pas à remonter les éventuels bugs rencontrés sur vos projets suite à la migration, cela garantira une version 7.0 des plus stables !

1 commentaire
Slt, je débute en PHP et je me rend compte que pas mal de versions se sont succédées ces dernières années.
Mais ton article est très bien compréhensible.
Merci !