
Le 4 Avril dernier, Xavier Hausherr, CTO chez Overblog, présentait à l’occasion du Symfony Live 2013 le processus de développement de son équipe.
Ce processus a été complètement revu dernièrement, et laisse derrière lui le traditionnel cycle en V au profit d’un processus agile adapté au fonctionnement d’Overblog.
METHODOLOGIE AGILE
Les besoins des produits d’Overblog évoluant très rapidement et les spécifications détaillées étant rarement fournies, l’équipe s’est tournée naturellement vers la méthodologie SCRUM pour encadrer ce nouveau processus de développement. Je ne reviendrai pas sur les bases cette méthode, vous pourrez trouver énormément de ressources la concernant sur internet, mais voici les ajustements effectués par l’équipe d’Overblog :
- Les sprints sont d’une durée de 2 semaines.
- L’incrément d’un sprint est mis en production le premier jour du sprint suivant.
- Le contenu du sprint est gelé le mercredi précédent la fin du Sprint afin de consacrer les 2 derniers jours aux tâches de debug et de refactorisation ainsi qu’aux réunions de fins de Sprint (démo et rétrospective)
- Une revue de code est organisée le dernier jour d’un sprint permettant aux membres de l’équipe de mettre en lumière des parties de code intéressantes venant d’être développées.
- Le poker planning est étalé sur l’ensemble du Sprint à raison de 30min tous les 2 jours. Cette mesure a été prise afin, d’une part, de ne pas avoir des sessions trop longues et, d’autre part, de pouvoir évaluer rapidement un item qui apparaîtrait au milieu d’un sprint.
PROCESSUS DE DEVELOPPEMENT
Afin de sélectionner un processus de développement adapté, Overblog a fixé le cahier des charges suivant :
- Coder sans mettre en péril le projet
- Travailler à deux ou plus sur des features
- Tester chaque fonctionnalité avant mise en production
- Intégration continue pour certaines fonctionnalités
- Release pour les grosses fonctionnalités
- Gestion des urgences
- Être accepté par l’équipe SCRUM
L’équipe s’est d’abord intéressée au « Git Flow ». Le Git Flow est un modèle de structure d’un repository Git présenté par Vincent Driessen (@nvie) dans son post « A successful Git branching model » début 2010. Il se présente de la façon suivante :
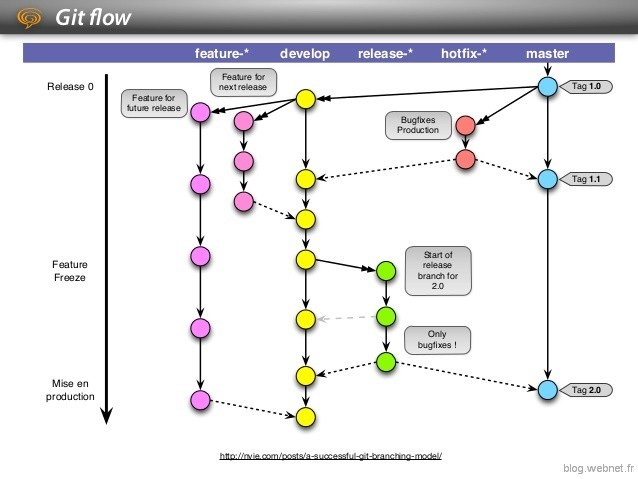
Dans ce modèle, le développement s’articule autour de la branche « develop » qui représente le dernier état stable du projet et de la branche « master » qui représente de son côté le dernier état livrable du projet.
Les branches de type « feature » permettent de cloisonner les développements de fonctionnalités et particulièrement ceux qui nécessite plusieurs sprints pour pouvoir être livrables. Une fois qu’une fonctionnalité est terminée et stable, elle est réintégrée à la branche « develop » via un merge.
Lors de la « feature freeze », on crée une branche de type « release » ayant pour vocation d’être livrée en production. C’est cette branche qui est testée, debuggée, refactorisée (les modifications étant également reportées sur la branche « develop »).
Une fois que la release est considérée livrable elle est mergée avec la branche « master » représentant l’état de la production.
Si des bugs importants font leurs apparitions en production, il est possible de créer une branche de type « hotfix » basée sur la branche « master » afin de corriger rapidement le bug. La correction, une fois testée, est alors réintégrée dans la branche « master » (pour pouvoir être livrée) mais également dans la branche « develop » afin que les prochaines versions en tiennent compte.
Il est également possible de travailler à 2 sur une même fonctionnalité en définissant des «GIT remote » pointant vers les repository GIT des postes locaux des développeurs.
Ce processus répond à plusieurs des besoins de l’équipe mais présente plusieurs inconvénients :
- Il n’y a pas de connexion centralisée
- Le merge peut être compliqué et la responsabilité du merge n’est pas indiquée
- Le moment où effectuer des tests n’est pas spécifié non plus
- Le nom de la branche « develop » n’est pas très significatif
Ces limitations avaient déjà été remarquées par Scott Chacon, évangéliste Git.
Ce dernier propose dans un article daté d’Août 2011 une approche similaire basée sur Github qu’il appelle « Github flow ».
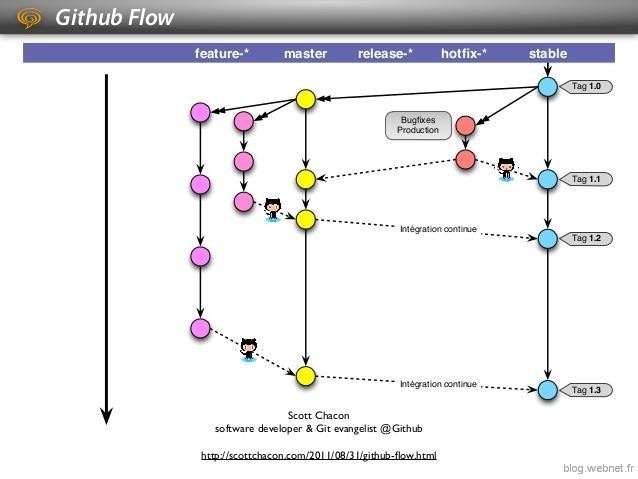
La branche « master » remplace la branche « develop » du Git Flow et la branche représentant l’état livrable devient la branche « stable ». On retrouve les branches de type « feature » et « hotfix » à l’identique mais les merges dans les branches « master » et « stable » (dans le cas d’un hotfix) se font à l’aide des pull requests de Github. Les modifications de la branche « master » sont réintégrées directement dans la branche « stable » via un processus d’intégration continue permettant de valider le code produit
Cette nouvelle méthode répondait plus largement aux besoins de l’équipe d’Overblog mais l’absence de release posait problème. Ils ont donc pris le parti de créer leur propre processus appelé modestement Overblog Flow;-)
Celui-ci reprend les points forts des 2 méthodes précédentes :
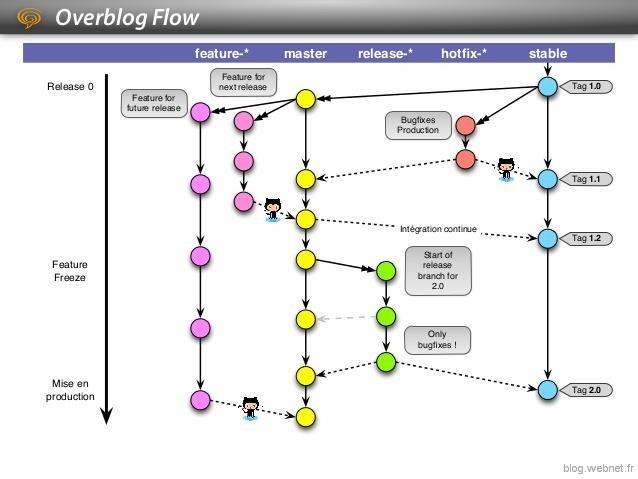
On y retrouve donc la structure principale de Github flow auquel des branches de types «release» ont été ajoutées. Leur utilisation n’est pas systématique, ainsi une feature urgente peut être mise en production rapidement via un processus d’intégration continue.
TESTS UNITAIRES ET FONCTIONNELS
Lors du développement, le développeur écrit et lance les tests unitaires dans son environnement local de développement. Une fois que la feature est considérée comme terminée par le développeur, il soumet une pull request au lead developer. L’incrément, une fois validé, est déployé sur un serveur de test afin de passer une série de tests via Jenkins :
- Tests unitaires PHP (PHPUnit)
- Tests unitaires JS (YUI Test)
- Qualité du code
- Respects des normes
- (…)
Une équipe « Qualité » est ensuite chargée d’écrire des tests fonctionnels couvrant la nouvelle fonctionnalité. Ces derniers sont également exécutés sur la plateforme de tests via Jenkins. Ils sont rédigés dans le langage Gherkin et exécutés via Cucumber.
L’incrément est ensuite déployé sur une plateforme de « staging », plus proche de la production (configuration des serveurs, données, etc.) . Il subit alors de nouveau une série de tests via Jenkins (tests unitaires et fonctionnels).
Si les tests sont concluants, l’incrément passe alors en production. Cette dernière étant également testée fonctionnellement chaque nuit.
CONCLUSION
Dans un esprit agile, Overblog a su composer sa propre méthodologie de travail en s’inspirant et en adaptant des méthodes existantes qui ont fait leurs preuves. Il est certain que cette méthode sera affinée au fur et à mesure des sprints dans les mois et années à venir, s’adaptant aux nouvelles contraintes techniques et humaines de l’équipe et aux nouveautés à venir mais l’ensemble semble déjà un succès au vu de la qualité du travail accompli, du nombres de blogs hébergés et des bonnes critiques sur la nouvelle version du site que l’on peut lire en général.
Vous trouverez ci-dessous le lien vers les slides de la présentation ainsi que les liens se rapportant aux articles cités.
REFERENCES
- Slides de la présentation : http://fr.slideshare.net/xkobal/git-flow-un-processus-de-dveloppement-agile
- Git flow : http://nvie.com/posts/a-successful-git-branching-model/
- Github flow : http://scottchacon.com/2011/08/31/github-flow.html
- Overblog : http://www.over-blog.com/
