
Qu’est-ce qu’une table temporelle ?
Une table temporelle, également appelée table système versionnée, permet comme une table traditionnelle de stocker nos différentes informations, à l’exception qu’elles enregistrent également l’historique de modification de chaque donnée. Le moteur de base de données va maintenir un état d’historisation de nos données et ce de façon automatique via les tables temporelles.
Ces tables temporelles sont apparues pour la première fois dans le standard SQL ANSI 2011 et IBM DB2 se targue d’être le premier à l’avoir implémenté.
Une nouvelle table peut être créée directement en type temporelle, mais on peut également y convertir une table existante.
Principe de fonctionnement
Le principe est relativement simple. Pour les requêtes traditionnelles, c’est-à-dire celles dont on souhaite les valeurs à l’instant présent, rien ne change.
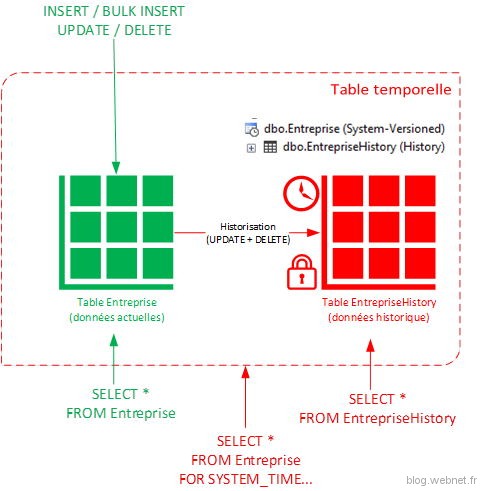
Lorsqu’une table est temporelle il y a 2 nouvelles colonnes présentes, communément nommées « SysStartTime » et « SysEndTime ». Ces deux colonnes de versioning système permettent de définir une période de validité de la donnée dans l’historique, et ce pour chaque ligne dans la table. Tout changement (INSERT, BULK INSERT, UPDATE, DELETE) sera automatiquement historisé.
A la création d’une table logique temporelle il y a deux tables physique créées :
- La table « standard » habituelle stockant les données actuelles
- La table versionné-système stockant les données modifiées (UPDATE) et supprimées (DELETE) ainsi que la plage de date pour laquelle la donnée était valide
La gestion des données entre ces tables est complètement transparente pour l’utilisateur. On peut requêter sur l’une ou l’autre des tables ainsi que sur l’ensemble du jeu de données à la manière d’une fusion.
Voici un schéma récapitulatif du process. En vert ce que qui concerne une table « standard » et en rouge ce qui est nouveau pour la temporalité :
Sous SQL Server les tables temporelles ne remplacent pas la fonctionnalité capture de données modifiées (Change Data Capture CDC). En effet, les tables temporelles stockent les modifications en table historique pour être conservé si besoin indéfiniment tandis que CDC utilise les logs de transaction pour retrouver les modifications, et ces modifications sont conservées pour une certaine courte période de temps.
La temporalité permet donc d’effectuer des opérations logique et non pas physique sur les données. Une ligne supprimée ne le sera pas de manière permanente.
Pourquoi les utiliser
Il y a plusieurs cas d’utilisation possible, comme :
- Auditer les données, par exemple pour connaître qui à modifié l’adresse du client la semaine dernière et quel était sa précédente valeur
- Facilement restaurer les données en cas de modification erronée
- Pallier à une malencontreuse perte de données
- Permettre la création de divers rapports et de tendances
Imaginez un site e-commerce, pour conserver les détails des commandes, il aurait fallu par exemple persister dans une nouvelle table liée à la commande les données du produit afin que le client puisse les consulter dans le détail de sa commande. Cela devient plus ennuyant si le produit a divers variantes (couleur, taille…), ou encore si on doit persister les adresses de facturation/livraison à l’instant de la commande. Si demain on vous demande d’afficher la fiche produit (incluant images, questions…) telle qu’elle était au moment de la commande c’est davantage plus problématique car alors il faudrait dupliquer une partie du schéma SQL du produit lié au produit commandé, ou sérialiser et stocker l’ensemble des données à ce moment précis. Autre problème, plusieurs clients commandant le même produit engendrera des informations dupliquées dans la table. On remarque que c’est compliqué et que ça peut le devenir rapidement encore davantage.
Pour faire autrement on pourrait le faire ainsi :
- Créer une table historique pour chaque table et la renseigner via des triggers. Bref réimplémenter la fonctionnalité temporelle
- Créer une table historique contenant l’ensemble des tables auditées avec un schéma similaire : Id (auto-incrémenté), TableName, NomTable, NomColonne, AncienneValeur, NouvelleValeur, DateModification, UtilisateurModification. Elle stockerait énormément de lignes et il faudrait mettre en place une stratégie d’indexation agressive en cas de requêtage fréquent dessus.
- Dans le point précédent, il ne serait pas aisé de retrouver l’ensemble des valeurs d’une ligne à un instant spécifique avec cette table. Il faudrait dans ce cas stocker dans AncienneValeur et NouvelleValeur l’ensemble des données de la ligne via une sérialisation. Entre alors en jeu une perte de performance sérialisation/désérialisation, un requêtage complexe si l’on souhaite dans notre requête ajouter une clause sur une valeur de cette donnée, et problèmes si le schéma de la table initiale est modifié et donc les données sérialisées se retrouvent désynchronisées du nouveau schéma.
C’est du développement supplémentaire, une complexification du schéma global de la base de données, de la documentation…
Avec des tables temporelles il n’y aurait aucune modification de schéma SQL ni de logique, on ne conserve que les IDs des produits/adresses ou toute autre relation temporelle, donc aucune perte de place ni duplication de données. Si l’on souhaite afficher la fiche produit au moment de la commande, les requêtes d’affichage de la page seraient exactement les mêmes avec en plus une clause Date données = DateCommande.
DBMS les supportant
Dans cet article nous allons utiliser SQL Server mais ce n’est pas le seul outil les supportant. Voici la liste complète à ce jour :
- Microsoft SQL Server 2016
- IBM DB2 version 10
- MariaDB 10.3
- PostgreSQL via extension temporal_tables
- Oracle 12c
- SAP HANA 2.0 SP03
- Ebean ORM
Comment y créer une nouvelle table
Pour pouvoir créer une table temporelle sous SQL Server il faut les prérequis suivants :
- Une clé primaire
- Deux colonnes de type datetime2 pour stocker les dates de début et fin de validité, généralement appelées SysStartTime et SysEndTime. Ces colonnes sont appelées colonne de période SYSTEM_TIME et peuvent être masquées via le flag HIDDEN. A noter que leurs valeurs sont en UTC.
- Compression par page par défaut
- Les CASCADE DELETE/UPDATE ne sont pas permis sur la table actuelle dans SQL Server 2016. A partir de SQL Server 2017 il est dorénavant possible de le faire.
Le script suivant va créer une table temporelle :
Si comme ici vous ne spécifiez aucun nom pour la table historique alors SQL Server va automatiquement en générer un avec la structure suivante dbo.MSSQL_TemporalHistoryFor_xxx, où xxx correspond à l’Id objet de la table principale.
Voici le résultat :
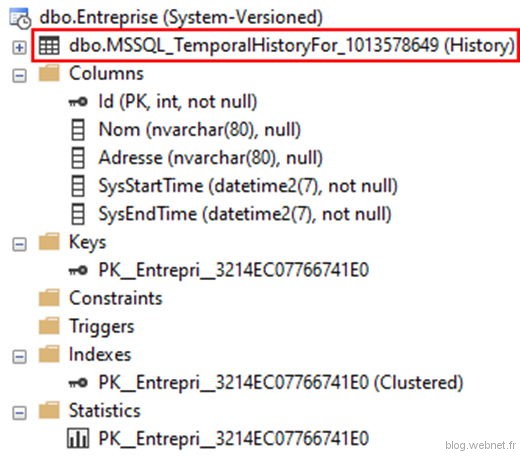
La table principale contient le suffixe « System-Versionned » et la table d’historique « History ». Vérifions ce que contient la table historique :
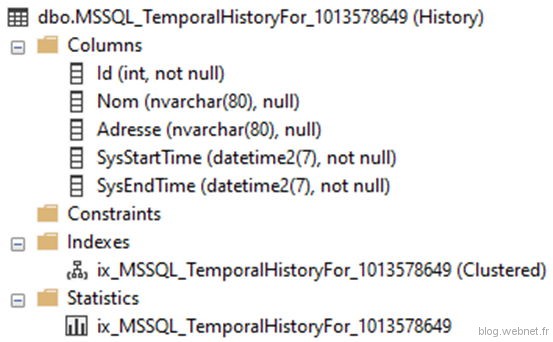
La table historique possède exactement les mêmes colonnes, mais sans aucune contrainte comme la clé primaire qui n’est plus auto-incrémentale. Il possède également son propre jeu d’index et de statistique. A savoir que la création de ses propres indexes sur la table d’historique est donc possible et permet grandement d’améliorer les performances des requêtes utilisant l’historique.
On peut également manuellement nommer la table d’historique, comme ici en « EntrepriseHistory » ce qui est plus pratique à écrire :
Résultat :
![]()
Il est toujours possible de supprimer la temporalité d’une table :
Il y aura ainsi 2 tables autonome :
![]()
Et de complètement supprimer ces tables :
Il est également la possibilité de les créer dans SQL Server Management Studio (SSMS) :
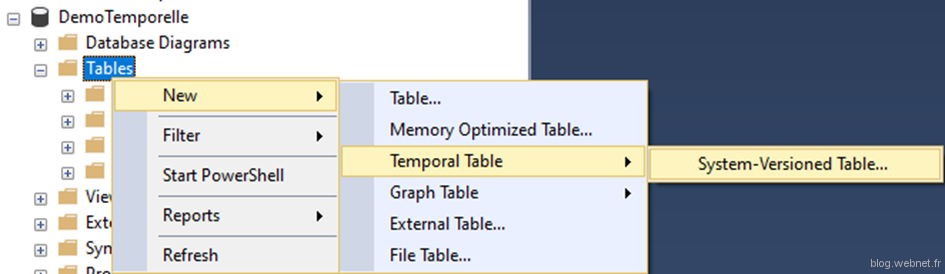
Mais cela ne fera que générer un script type de création. Si les scripts SQL ne sont pas votre tasse de thé, alors vous pouvez créer votre table « standard » comme habituellement via l’interface graphique de SSMS, puis la convertir en table temporelle.
Comment rendre une table existante temporelle
Il est possible d’activer la temporalité sur une table existante. Par exemple créez une table Employe (via SQL ou SSMS) :
Résultat :
![]()
Pour convertir une table en table temporelle il faut le faire en 2 opérations, la création des colonnes date système puis la conversion en temporalité :
Résultat :
![]()
Notez le mot clé « HIDDEN » utilisé pour les dates système. Celui-ci permet de masquer les deux colonnes de date dans la requête de sélection.
Il est également possible de le faire en utilisant une table d’historique existante. Pour vérifier que les périodes de durée ne se chevauchent pas, utiliser la clause DATA_CONSISTENCY_CHECK.
Leur requêtage
Ajoutons un peu de données à nos deux tables :
Récupérons les résultats :
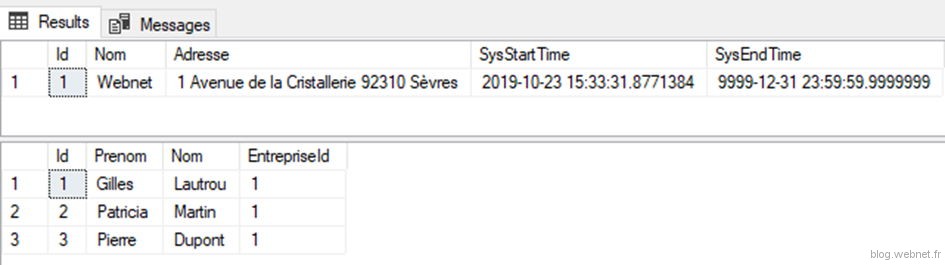
On remarque que dans la sélection des employés n’apparaissent pas les colonnes de date système. C’est normal car nous les avions définies comme « HIDDEN ». Pour les afficher il faut les sélectionner de façon explicite :
Vérifions qu’il n’y a aucune donnée dans les tables historique (vu précédemment les INSERT et BULK INSERT ne sont pas historisés, seulement les UPDATE et DELETE)
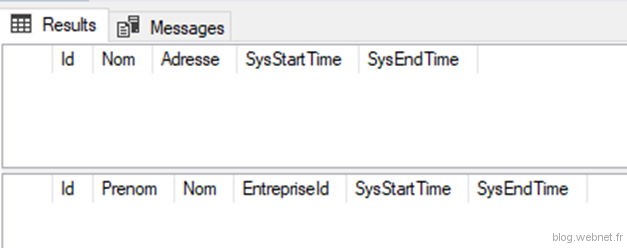
C’est normal qu’il n’y ait pas d’historique puisque les lignes n’ont pas été modifiées.
Supprimons un employé :
Vérifions qu’il soit correctement supprimé :
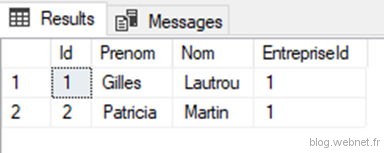
Vérifions la table d’historique :

Récupérons l’ensemble des employés ayant déjà été enregistré, donc y compris les supprimés :
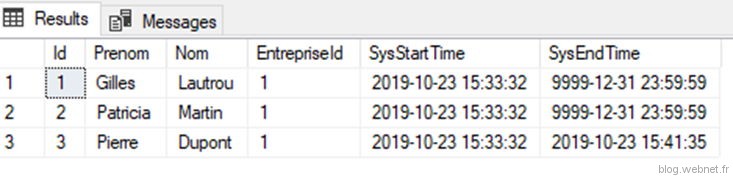
On remarque que l’employé supprimé est bien présent et supprimé le 23/10/2019 à 15h41.
Notez l’utilisation de la clause « FOR SYSTEM_TIME ALL » qui permet d’agréger les données actuelles avec leur historique (fusion des 2 tables).
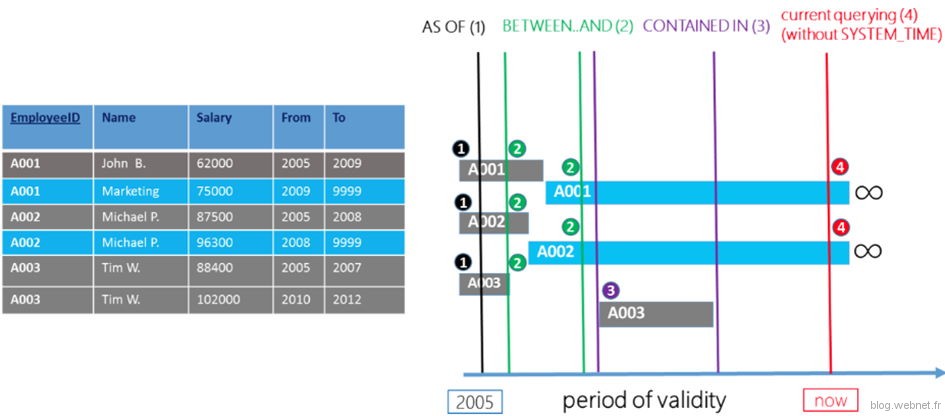
La clause « FOR SYSTEM_TIME” peut posséder les critères suivants :
- ALL: Historique complet (fusion des 2 tables) : Tout
- CONTAINED IN(<start_date_time> , <end_date_time>) : Lignes active exclusivement dans la période de date (et pas en dehors) : SysStartTime >= start_date_time ET SysEndTime <= end_date_time
- FROM<start_date_time>TO<end_date_time> : Lignes ayant été active sur au moins une partie de la période de date : SysStartTime < end_date_time ET SysEndTime > start_date_time
- BETWEEN<start_date_time>AND<end_date_time>: Similaire à FROM TO, sauf que sont également incluses les lignes devenues actives sur la limite supérieure TO : SysStartTime <= end_date_time ET SysEndTime > start_date_time
- AS OF<date_time> : Valeur des données à un instant t : SysStartTime <= date_time ET SysEndTime > date_time
Voici sur le schéma de la documentation Microsoft visuellement ce que ça représente (lignes bleues = données actives, lignes grises = données supprimées) :
Comme énoncé précédemment les colonnes de période système ne sont pas directement modifiable car ce sont des colonnes système :
Comme nous possédons l’historique des données, il est possible d’automatiser la restauration des données d’une ligne via une procédure stockée. Voici la procédure pour restaurer n’importe quelle version historisée des modifications d’un employé :
Faisons maintenant une modification du nom de l’employé 1 puis un rollback de notre modification :
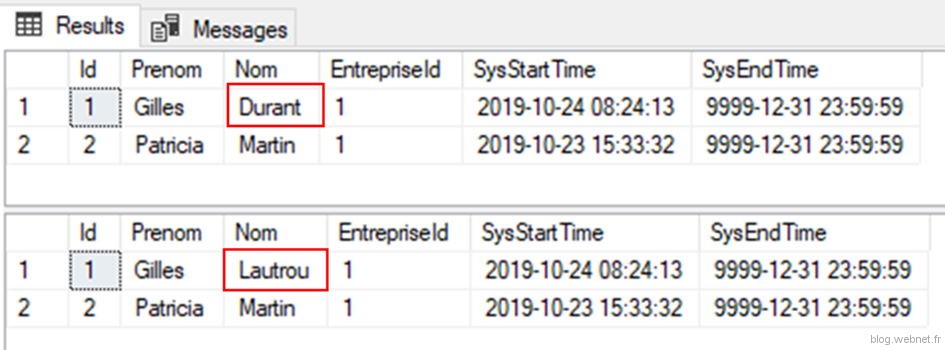
Nous avons précédemment vu comment récupérer la donnée actuelle ainsi que la donnée historisé. Voyons maintenant comme le faire via des jointures. Pour cela, modifions l’adresse de l’entreprise :
Si je souhaite récupérer la liste des utilisateurs et leur entreprise :

Nous avons bien la dernière version de nos données.
Maintenant si nous souhaitons récupérer l’ensemble des employés appartenant à l’entreprise en date du 23/10/2019 à 15h40 :

On récupère bien l’employé 3 qui a pourtant été supprimé depuis. Notez également que la date de temporalité utilisée n’a pas été appliquée à la jointure puisque l’adresse de l’entreprise est la dernière version et ayant été modifiée après cette date.
La directive de temporalité doit donc être appliquée sur chaque table dans la requête. Si l’on souhaite l’historique il faut systématiquement le préciser :

Cela peut sembler embêtant d’avoir à respécifier FOR SYSTEM_TIME pour chaque jointure, mais l’avantage c’est que dans une même requête on peut du coup les mixer ce qui ouvre la voie à toute sorte de possibilité de requêtage.
Cependant il n’est pas possible de définir SYSTEM_TIME dynamiquement à partir d’une requête, par exemple :

Considérations à prendre en compte
Voici des limitations sur la table :
- Les tables ne peuvent pas être FILETABLE
- L’historique ne peut pas avoir de contraintes
- Les instructions INSERT et UPDATE ne peuvent pas assigner de valeur aux colonnes de périodicité SYSTEM_TIME
- Les données dans la table historique ne peuvent pas être modifiées
Toutefois pour les deux derniers points il reste possible de le réaliser directement en retirant le versioning système, effectuant les modifications, puis en le réactivant.
Tout l’historique des données est conservé donc il faut correctement dimensionner la machine si beaucoup de modifications sont effectuées sur les tables temporelle, quitte à splitter sa table de façon à rendre temporelle que les données qui ont besoin de l’être. Il y a toutefois des solutions, comme le partitionnement de table mais surtout depuis SQL Server 2017 utiliser une stratégie de rétention des données temporelles.
Certaines modifications de schéma sont limitées, par exemple l’ajout du type IDENTITY. Cependant comme alternative il est possible de temporairement désactiver le versioning système, effectuer les modifications, puis réactiver le versioning.
Voici un exemple de script pour ajouter la colonne nommée Reference et de type entier auto-incrémenté. Cette colonne ne pourra pas être auto-incrémentée dans la table d’historique puisque chaque ligne n’étant pas une donnée mais un historique d’une donnée, donc créer un type entier avec une valeur par défaut pour prendre en compte les anciennes données.
Un inconvénient des tables temporelles rencontré à l’usage est que dans notre requête on ne peut spécifier qu’une seule date. Par exemple, sur la page de listing des commandes, on ne peut pas en une seule requête récupérer les données à l’instant t de création de chaque commande. Il faut le faire commande par commande. Il y a toutefois des alternatives comme utiliser AS SYSTEM_TIME ALL puis vérifier manuellement que les lignes soient comprises dans la page SysStartTime et SysEndTime.
Autre point peut être dérangeant, la plupart des modifications sur les tables temporelles doivent se faire en script SQL. Espérons que SSMS prenne rapidement pleinement en charge cette nouvelle fonctionnalité.
Conclusion
Nous avons vu au travers de cet article que les tables temporelles sont extrêmement simples à mettre en place et s’avèrent extrêmement pratiques dans certains scénarios qui nécessitent le suivi d’historique de modification des données. Elles sont très bien intégrées à SQL Server 2016 et plus particulièrement 2017. On peut également s’en servir pour corriger des erreurs de suppression/perte de données. Pour le requêtage des données historiques rien que de plus simple d’ajouter « FOR SYSTEM_TIME » avec la date précise ou plage désirée de l’état des données. Pour aller plus loin on peut même imaginer des scénarios de détection d’anomalie en analysant l’évolution d’une valeur de colonne comme le solde quotidien d’un compte bancaire.
Toutefois la principale limite réside dans le fait que tout l’historique des données est persisté, et que pour les tables avec des modifications fréquentes cela pourra rendre la taille des données conséquente, donc dimensionner en conséquence et prévoir au besoin un mécanisme de purge de l’historique. Il faut donc étudier comment sa table sera utilisée et se poser les bonnes questions, est-ce que la table contient 500 colonnes varbinary(max) dont chaque ligne est modifiable toute les minutes ? En revanche, dans certains scénarios (passage de commande de fiche produit) cela peut avoir un impact positif sur la taille, donc à mesurer en fonction de ses besoins.
Nous avons utilisé avec succès les tables temporelles dans les projets Microsoft .NET au sein de Webnet, au travers notamment d’une application complexe d’e-commerce. Les tables temporelles nous ont permis de grandement simplifier notre schéma SQL et réutiliser nos requêtes non-temporelles en fonction du cas d’utilisation. Le développeur n’a pas à se préoccuper si la donnée historique se retrouve dans une autre table aplatie ou un schéma d’historique dupliqué.
Dans la seconde partie de cet article nous allons voir comment interagir avec ces tables via l’ORM Entity Framework.
