
Le projet
Dans le cadre de PLANET (Plan d’excellence technologique), nous souhaitions nous lancer dans un projet en rapport avec le monde des objets connectés.
C’est comme cela que lors d’un brainstorming, nous avons émis l’idée de créer un « assistant » d’accueil basé sur une des nouvelles plateformes d’IoT (Internet of Things) qui sont apparus récemment.
Nous avions le choix entre plusieurs solutions : RaspberryPi, Galileo (Intel), Adruino, etc. …
Nous avons finalement choisi la RaspberryPi 2 qui est une des plus performantes par rapport au prix et qui, de plus, est suivie et supportée par une très grande communauté active sur internet.
Les différentes solutions
Nous étant mis d’accord sur la base de travail de notre assistant, nous nous sommes mis à la recherche de solutions open-source existantes permettant de gérer les commandes vocales.
Nous avons trouvé plusieurs solutions et avons finalement sélectionné deux solutions pour tenter une première implémentation : JASPER et S.A.R.A.H.
JASPER est une solution qui nous a semblé prometteuse et qui a l’avantage d’avoir été conçue pour fonctionner sur RaspberryPi.
Malheureusement après nos premiers tests, nous nous somme rapidement aperçu d’une limitation assez gênante : La majorité des moteurs de STT (Speech to Text) qui sont compatibles avec la solution ne supportent pas très bien la langue française.
Le seul moteur de reconnaissance qui gérait très bien la langue de Molière était celui fourni avec l’API Google. Là encore, il y’a un gros bémol : L’API possède une limitation du nombre d’appels d’environ 50 appels/jour. Cela a fini par sceller le sort de Jasper en ce qui nous concerne.
Notre solution devant être un assistant d’accueil dans nos locaux (en France), cela n’était tout simplement pas viable sur le plan pratique.
S.A.R.A.H. nous a finalement convenu parfaitement.
La solution se base sur la reconnaissance vocale de Windows qui gère très bien la langue française de manière native.
S.A.R.A.H. n’étant compatible qu’avec Windows, nous avons donc décidé d’installer S.A.R.A.H. sur un ordinateur et de déporter la capture audio et vidéo sur la RaspberryPi grâce au module RTP de S.A.R.A.H.
Principe de fonctionnement de S.A.R.A.H.
La solution S.A.R.A.H. est donc conçue pour fonctionner sur Windows.
Elle se décompose en deux parties :
- Le client: C# (avec gestion de la Kinect) pour la gestion de la reconnaissance de la voix, des gestes, des visages et des des QRCodes.
- Le serveur: NodeJS (ExpressJs) pour la communication et l’interaction avec le reste des fonctionnalités et les objets connectés.
La partie « client » recueille les commandes (vocales en ce qui nous concerne) et après reconnaissance les transmet au serveur NodeJs.
Grâce au fichier de grammaire défini dans chacun de nos plugins (NodeJs) S.A.R.A.H. détermine le code à exécuter.
Il suffit donc de coder la fonctionnalité et de renvoyer une réponse au format texte que S.A.R.A.H. va faire prononcer par Windows.
Architecture de la solution
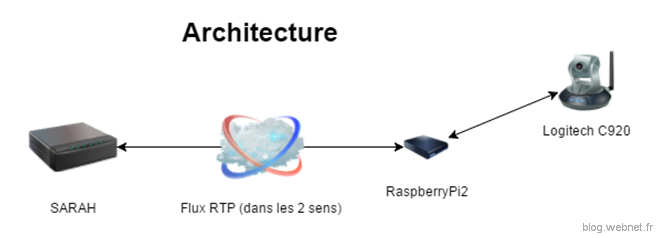
La solution complète que nous avons retenu est constituée de :
- Serveur Windows (un simple ordinateur peut faire l’affaire)
- RaspberryPi 2 model B avec un dongle Wifi
- Une webcam USB Logitech HD Pro C920 avec micro intégré
- Haut-parleurs externes connectés sur le port Jack de la Raspberry
Une transaction classique se déroulera de la façon suivante :
1. La Raspberry capture l’audio et la transmet à S.A.R.A.H. via RTP grâce à FFMpeg
2. S.A.R.A.H. effectue le traitement et donne sa réponse audio
3. La réponse audio est transférée à la RaspberryPi via RTP grâce à FFMpeg et Virtual Audio Capture Grabber
4. La Raspberry « joue » la réponse audio reçu sur les haut-parleurs
Installation de S.A.R.A.H.
Nous avons donc décidé d’installer S.A.R.A.H. à l’aide de l’installateur blog.encausse.net/sarah/
Nous nous somme basé sur la version 4.0 Bêta, le module RTP ne fonctionnant pas sur la version 3.
Nous reviendrons plus tard sur cette fonctionnalité.
Nous avons également installé les modules suivants pour faire fonctionner la solution :
- FFMpeg
- Python 2.7
- OpenCV 2 pour Python
- virtual-audio-capture-grabber-device
Installation RaspberryPi
Nous avons choisi de nous baser sur la distribution Raspbian.
Il nous a ensuite fallut installer :
- FFMpeg depuis les sources (en suivant cet excellent tutoriel)
- Installer Python avec tous les utilitaires tel que pip et virtualenv (raspberry.io/wiki/how-to-get-python-on-your-raspberrypi/)
- Installation d’OpenCV pour python (en suivant ce tutoriel)
Interconnexion S.A.R.A.H. et RaspberryPi
Une fois que le client et le serveur S.A.R.A.H. sont démarrés, nous allons pouvoir leur envoyer des commandes vocales.
Pour pouvoir capturer l’entrée audio depuis la Raspberry on lance la commande suivante :
arecord -D hw:0,0 -f S16_LE -r 16000 -c 2 -t wav | ffmpeg -i pipe:0 -bufsize 64k -ac 2 -f "volume=20dB" -ar 16000 -acodec pcm_s16le -f rtp rtp://[IP_SERVER_SARAH]:7887-D hw:0,0 » correspond au device de capture.
Pour trouver l’id de votre périphérique de capture, il vous suffira de lancer la commande « arecord -l », ils seront alors tous listés avec un ID de « device » et de « subdevice »
Maintenant les commandes vocales devraient être reconnues par S.A.R.A.H. mais la réponse audio se fera entendre sur l’ordinateur sur lequel S.A.R.A.H. est installée.
Pour pouvoir faire suivre les réponses vers la RaspberryPi. Il faut lancer le l’utilitaire de Virtual Audio Capture Grabber
Démarrer > Tous les programmes > Screen Capture Recorder > Record > broadcast > Setup local audio broadcast streaming server
Ensuite lancer l’invité de commande de Windows puis exécuter la commande suivante :
ffmpeg -f dshow -i audio="virtual-audio-capturer" -acodec libmp3lame -f rtp rtp://[IP_RASPBERRY_PI]:7888Maintenant, Il suffit de parler dans le micro de la webcam reliée à la Raspberry et ainsi recevoir la réponse instantanément sur la sortie audio.
Mise en place de la reconnaissance faciale
La mise en place de la reconnaissance faciale est décrite en détail dans l’article suivant : Reconnaissance faciale avec OpenCV
Je vais quand même décrire le principe de fonctionnement que nous avons mis en place.
Nous avons décomposé la reconnaissance faciale en deux parties.
En effet, principalement pour des raisons de performances, nous avons découpé la reconnaissance faciale comme suit :
1. Le script de détection de visages est lancé sur la Raspberry en tâche de fond
2. Une fois qu’un ou plusieurs visages sont détectés, la ou les photos découpées des visages sont transmises sur le serveur S.A.R.A.H. (qui est également un serveur Web NodeJs)
3. Le contrôleur coté S.A.R.A.H. dépose les fichiers dans un dossier en attente de traitement et met à jour une table avec le nombre de personnes détectées devant la Raspberry
4. Le script de reconnaissance faciale est lancé sur le même serveur ou se situe S.A.R.A.H.
5. Ce script scanne en permanence le dossier contenant les photos déposées par le détecteur de visages
6. Il va ensuite effectuer la reconnaissance faciale et loguer les noms des personnes reconnues en BDD
7. Il suffit désormais de faire une requête en BDD depuis n’importe quel handler de commande S.A.R.A.H. pour savoir si une ou plusieurs personnes se situent devant la Webcam et si elles ont été reconnues.
Ainsi, nous pouvons personnaliser encore plus les réponses de l’assistant et imaginer des questions du type « S.A.R.A.H. est-ce que J’ai des RDV aujourd’hui ? », la réponse devenant contextuelle à l’interlocuteur de S.A.R.A.H qui interrogera par exemple le calendrier Outlook de la personne reconnue.
Difficultés rencontrées
Voilà maintenant notre solution entièrement fonctionnelle. Mais cela n’a pas été une promenade de santé.
Nous avons en effet rencontrés de nombreuses difficultés que nous avons eu à surmonter pour arriver à une solution fonctionnelle. Je ne citerais que les 2 principales :
La transmission audio
La transmission audio n’a pas été simple à mettre en place au début car nous avions utilisé la première webcam que nous avions eue sous la main, pensant que cela pourrait faire l’affaire.
Ainsi, nous avons été incapables de faire reconnaître quoi que ce soit à S.A.R.A.H. via la transmission RTP jusqu’à ce que nous changions de Webcam.
Le fait de de passer sur une webcam avec une capture audio digne de ce nom, nous a permis de trouver notre salut.
Pensez donc à vous équiper d’une webcam disposant d’un bon micro. De notre côté, nous avons trouvé notre bonheur via la Logitech HD Pro C920.
Performances
Au début, nous avions décidé de mettre la capture audio, la détection de visages et la reconnaissance faciale sur la Raspberry. Nous avions surestimé grandement la puissance de cette dernière et nous nous sommes retrouvé avec des décalages de détection/reconnaissance faciale de l’ordre de 4 secondes, avec des pointes de consommation mémoire et CPU de l’ordre de 99%.
Après de nombreux tests nous avons finalement conservé uniquement la détection de visage sur la Raspberry et avons déporté la reconnaissance faciale sur un serveur bien plus puissant.
Conclusion
Cet article décrit le cheminement de notre réflexion pour mettre en place un assistant d’accueil, en intégrant des solutions open source et peu coûteuses.
On peut voir qu’aujourd’hui, il est relativement simple (en étant un peu bidouilleur) de mettre en place ce genre d’installation.
La seule limite est finalement l’imagination et les possibilités d’interfaçage avec d’autres services ou fonctionnalités.
Nous allons continuer à améliorer notre solution et espérons bientôt pouvoir publier une vidéo de démonstration de notre assistant dans des conditions d’utilisation normales.
N’hésitez pas à aller voir notre vidéo YouTube sur ce sujet.

2 commentaires
Super projet. Il existe aussi « Jarvis » qui a aussi été conçu pour Raspberry Pi avec une interface d’installation et d’utilisation ultra-simples. Il fonctionne très bien en français aussi bien en local (snowboy) ou grâce à une api web (bing, google, wit). Plus d’infos ici:
https://github.com/alexylem/jarvis/wiki
Super intéressant comme projet. Je viens de voir que S.A.R.A.H V4 (en cours de développement) est maintenant porté sur Linux 🙂
Donc si on peut tout mettre sur le Raspberry ça évite d’avoir a connecter une machine Windows en plus.